Base64
Base64 是一种把 二进制数据文本化 的编码方式:它把任意字节流(图片、文件、密钥、压缩数据等)转换成只包含 A–Z、a–z、0–9、+、/(以及用于补齐的 =)这些可打印字符的字符串,方便在只适合传文本的场景里传输和存储(比如邮件、URL 参数、JSON、HTTP 头等)。注意:Base64 不是加密,只是编码,任何人都能解回原始数据。
Base64 的原理¶
(1) 核心思想¶
3 字节 → 4 个字符
Base64是一种基于64个可打印字符来表示二进制数据的表示方法。由于\(\log_{2}64=6\),所以每6个比特为一个单元,对应某个可打印字符。3个字节相当于24个比特,对应于4个Base64单元,即3个字节可由4个可打印字符来表示。在Base64中的可打印字符包括字母A-Z、a-z、数字0-9,这样共有62个字符,此外两个可打印符号在不同的系统中而不同。一些如UUencode的其他编码方法,和之后BinHex的版本使用不同的64字符集来代表6个二进制数字,但是不被称为Base64。
- 原始数据是按 字节(8 bit)来的。
- Base64 把数据按 3 个字节(3×8=24 bit)分组。
- 每 24 bit 再切成 4 组 6 bit(4×6=24 bit)。
- 每个 6 bit 的数值范围是 0~63,刚好能用 64 个字符来表示,于是就去“字母表”里查表得到字符。
Base64 标准字母表索引通常是:
- 0–25 →
A–Z - 26–51 →
a–z - 52–61 →
0–9 - 62 →
+ - 63 →
/
所以本质就是:把 24 位切成 4 个 6 位,然后按索引映射成字符。
(2) 具体流程(编码)¶
假设有 3 个字节:b1 b2 b3(每个 8 bit)
- 拼成 24 bit:
b1(8) | b2(8) | b3(8) - 切成 4 段:
s1(6) s2(6) s3(6) s4(6) - 对每段
si计算它的十进制值(0~63) - 去 Base64 字母表取对应字符,输出 4 个字符
用位运算写得更“底层”一点(帮助理解):
i1 = (b1 >> 2) & 0x3Fi2 = ((b1 & 0x03) << 4) | (b2 >> 4)i3 = ((b2 & 0x0F) << 2) | (b3 >> 6)i4 = b3 & 0x3F然后i1..i4分别映射到字母表字符。
(3) 为什么会有 =¶
当输入字节数不是 3 的倍数时,最后一组不够 24 bit,就要补齐,让输出长度总是 4 的倍数(便于解析)。
- 剩 1 个字节(8 bit):
实际只有 8 bit,需要凑成 24 bit。做法是后面补 0 到 24 bit,然后仍切成 4 个 6-bit。
但真正有效的只有前 2 个 Base64 字符(因为 8 bit 只能产生 2 个 6bit 片段的有效信息),后 2 个字符用
==表示补齐。 - 输出形式:
XX== - 剩 2 个字节(16 bit):
同理补 0 到 24 bit。有效的会有前 3 个 Base64 字符,最后 1 个字符用
=。 - 输出形式:
XXX=
所以:
- 余 0 字节 → 不带
= - 余 1 字节 →
== - 余 2 字节 →
=
(4) 解码过程(反向还原)¶
解码就是把流程倒过来:
- 每 4 个 Base64 字符一组
- 每个字符查表得到 0~63 的 6-bit 值
- 4×6=24 bit 拼回去
- 再切成 3 个 8-bit 字节输出
- 遇到
=就知道末尾哪些字节是补出来的,不输出这些补的部分
(5) 空间开销与“为什么是 64”¶
- Base64 把每 3 字节 变成 4 字符,如果按 1 字符 1 字节存储(ASCII/UTF-8),体积大约变为:
4/3 ≈ 1.333...→ 膨胀约 33%- 选择 64 是因为:
2^6 = 64,用 6 bit 刚好表示 64 种符号- 输出字符能选成“基本可打印字符”,适配早期和现代的文本通道
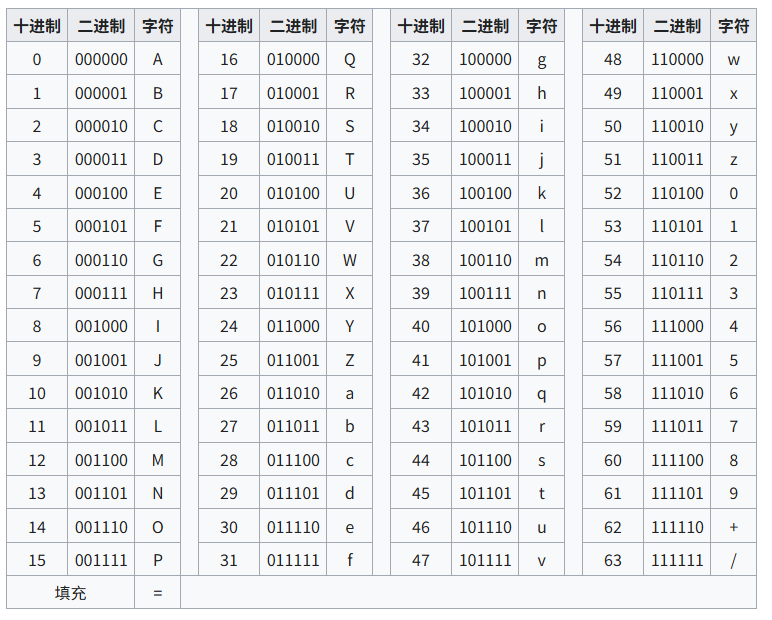
RFC 4648 标准的 Base64 索引表¶
例子¶
例1.无需补=¶
为大家举个例子,Man 的编码过程:
M a n 的ASCII十进制是:77 97 110
转换为24位的(\(3×8=24\) Bit)二进制:01001101 01100001 01101110
把这24位的二进制每6个一组切开,得到4组6 Bit 值(\(24÷6=4\)):010011 010110 000101 101110
根据Base64字母表查找对应字符的索引
所以索引序列是:19 22 5 46
查Base64字母表映射成字符:
Base64 字母表(标准那套)从 0 开始:0->A, 1->B, ... 25->Z, 26->a ... 51->z, 52->0 ... 61->9, 62->+, 63->/
因此:
- 19 →
T - 22 →
W - 5 →
F - 46 →
u
最终结果:Man → TWFu
例2.补=¶
以字符 M 为例子,ASCII值等于 77 ,转为二进制得到 01001101,由于只有1字节,不够3个字节,所以先进行补0:01001101 000000000 00000000,接着按6 bit进行切分:010011 010000 000000 000000,再转十进制的索引:
010011= 19010000= 16000000= 0000000= 0
索引:19 16 0 0
查表转为字符:
- 19 →
T - 16 →
Q - 0 →
A - 0 →
A
得到:TQAA
因为原始数据只有 1 个字节,实际只够生成 前 2 个 Base64 字符,后面 2 个字符是补出来的,所以用 == 标记:
最终:"M" → TQ==
例3.解码¶
以UQ==为例子,解码过程如下:
Base64 索引表规则:A=0 ... Z=25 ... a=26 ... 0=52 ... +=62 /=63
U是大写字母:A=0,所以U是第 21 个(从 0 开始)→ 20Q→ 16=、=:padding(填充),不代表数据
把索引转 6-bit:
- 20 →
010100 - 16 →
010000
拼成 24 bit(padding 对应补 0)
连起来:
010100010000000000000000
按 8 bit 切成 3 个字节
010100010000000000000000
根据 == 丢弃补齐字节
== 表示原始数据只有 1 个字节,所以只取第一个字节:
01010001 = 十进制 81 = ASCII 字符 'Q'
所以:UQ== → Q
练习题¶
题目地址:NO.0502 - Base64
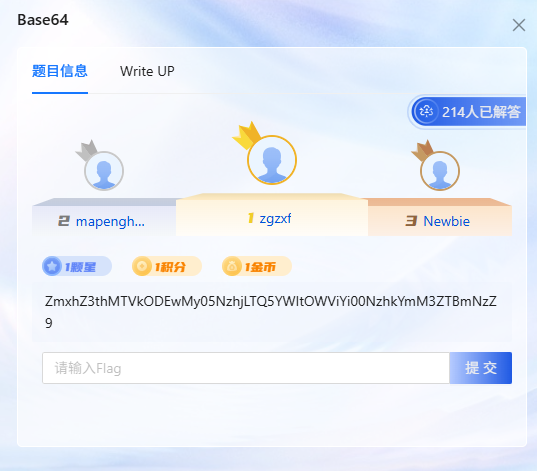
- 题目名称:Base64
- 题目难度:1
- 题目ID:NO.0502